

Real-time object detection part 1: Understanding SSD
Real-time object detection part 1: Understanding SSD

Real-time object detection: Understanding SSD
This post explains the working of the Single-Shot MultiBox Detector along with a code walkthrough
Object detection refers to the task of identifying various objects within an image and drawing a bounding box around each of them. A few examples are shown below to illustrate this better:

A lot of research has happened in this domain and the most commonly heard object detection algorithm is You Only Look Once (YOLO), which was the first effort towards obtaining a real-time detector and ever since it was introduced, it has undergone several updates. A major problem with the first version of YOLO was that its accuracy was very low compared to the state-of-the-art detectors of that time, all of whom operated in two stages: the first stage generated a list of proposals or guesses for where the objects could be within the image and the second stage classified each of the proposed boxes. For more details on how two-stage detectors work, follow this blog post. YOLO belongs to the category of one-stage detectors which remove the proposal generation step and predict the class scores along with the bounding box coordinates directly from the image in an end-to-end framework. Single-Shot Multibox Detector (SSD) was the first one-stage detector to achieve an accuracy reasonably close to the two-stage detectors while still retaining the ability to work in real-time. There have been a lot of efforts towards making one-stage detectors surpass the accuracy of two-stage detectors by tackling several issues with SSD and adding an additional stage of refinement in the one-stage pipeline, but most of them use SSD as the starting point. In his post, I’ll explain each and every component of SSD in detail. Throughout the post, I’ll refer to this excellent implementation of SSD in PyTorch to map the concepts with the corresponding code samples.
1. Understanding Default Boxes
The key idea underlying SSD is the concept of default boxes (or anchors). Don’t worry if you have a lot of questions by the end of this section. This section is just meant to give you a high-level picture and a flavour for the things to come.
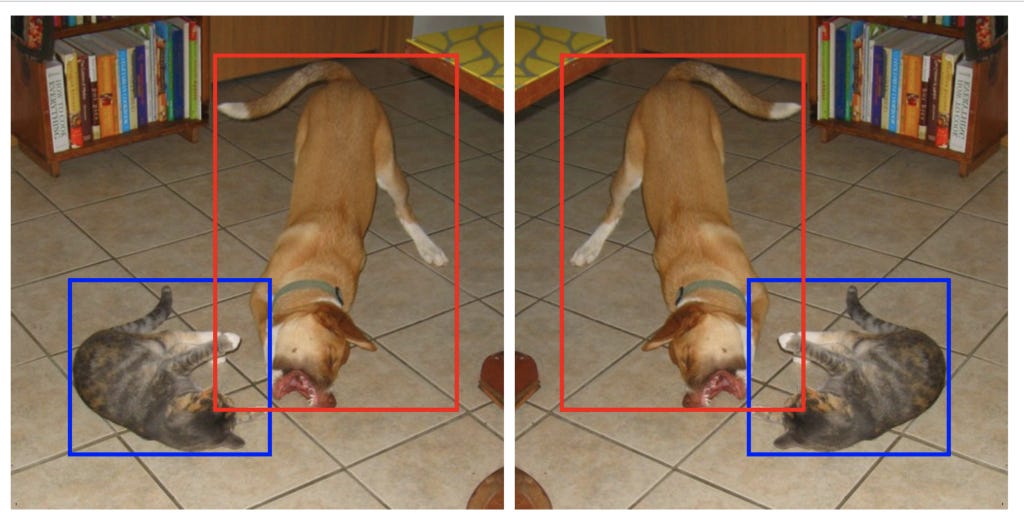
Default boxes represent carefully selected bounding boxes based on their sizes, aspect ratios and positions across the image. SSD contains 8732 default boxes. The goal of the model is to decide which of the default boxes to use for a given image and then predict offsets from the chosen default boxes to obtain the final prediction. If this sounded like a lot of jargon, stay with me. The following example and the subsequent sections should clear this further. But you need to keep coming back to this point and make sure you are very clear about it. The image below contains objects of two different scales and aspect ratios. We know that as we keep adding convolutional layers, the resolution of the feature map keeps reducing and hence, the receptive field of each cell of the feature map keeps increasing. Thus, earlier layers, having a smaller receptive field are better suited to detect smaller objects whereas later layers, having larger receptive field, can detect larger objects better.
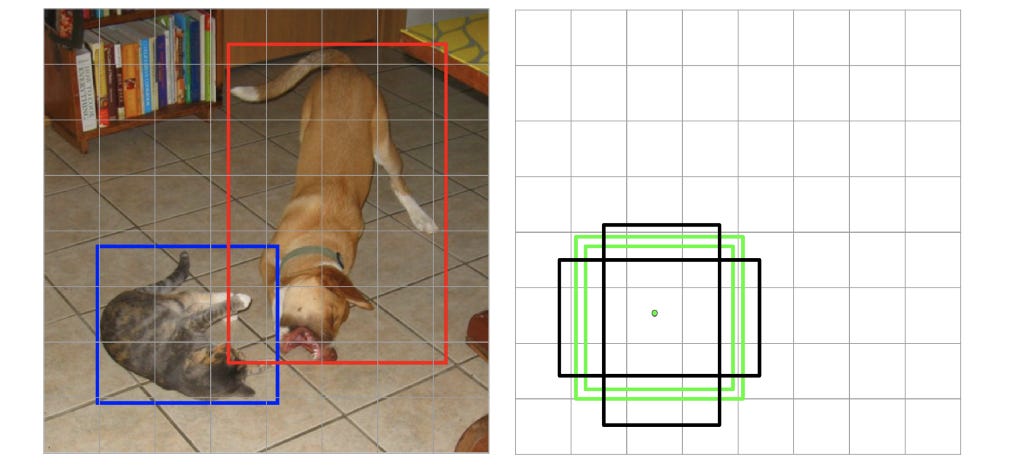
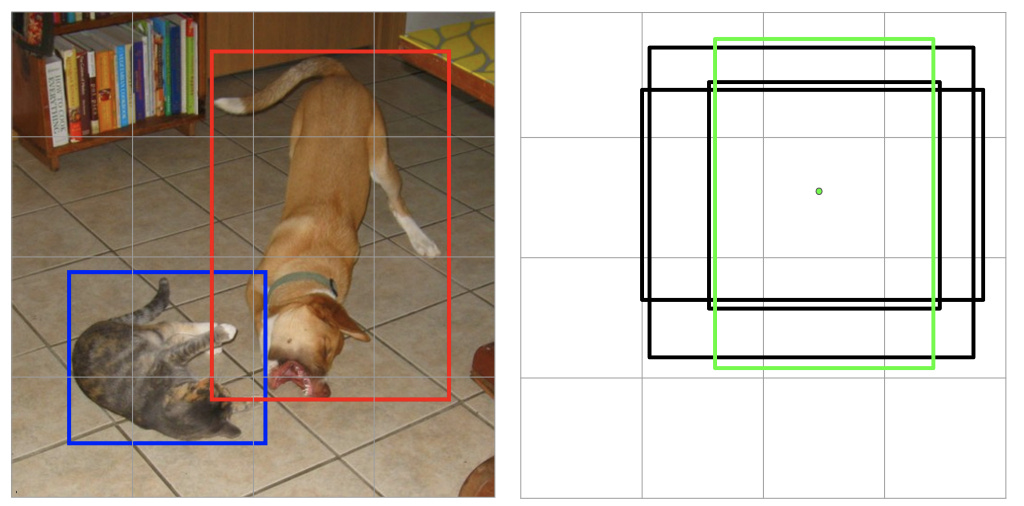
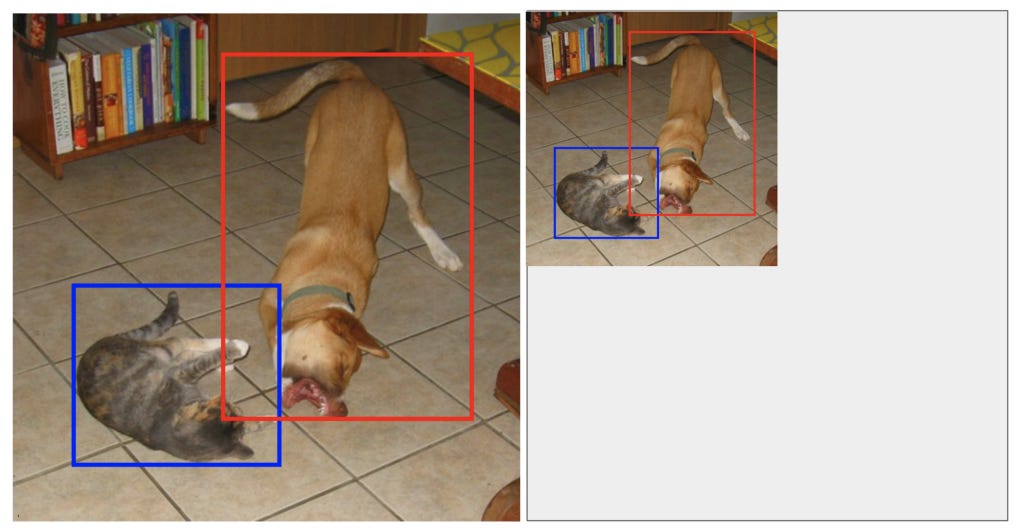
In the image above, the green (positive) boxes are the default boxes that match at least one ground truth (cat, in case of the left one, and dog, in the right one) whereas the black (negative) default boxes are those that didn’t get matched to any ground truth. Matching here means assigning a label to a default box, positive or negative. I’ll talk about this in more detail later, but the essence here is that certain default boxes are matched to certain bounding boxes in the ground truth while the rest are considered negative. From a high-level, the network is trained to perform two tasks:
i) Classify which amongst its 8732 default boxes are positive;
ii) Predict offsets from the positive default box coordinates to obtain the final predicted bounding boxes.
2. Architecture
The architecture of SSD consists of 3 main components:
i) Base network
ii) Extra feature layers
iii) Prediction layers
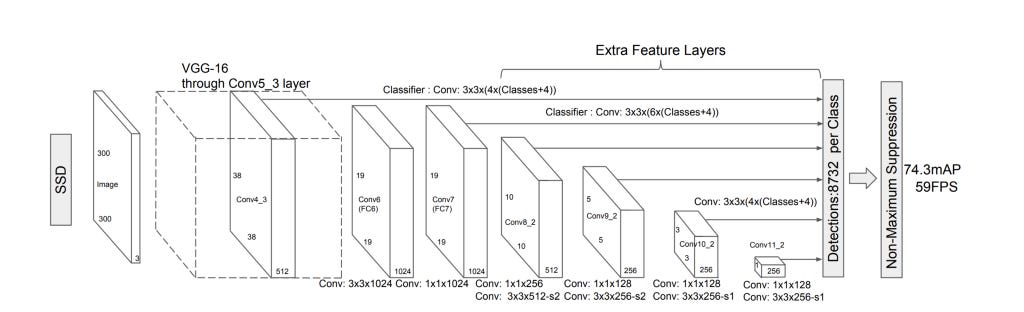
The base network is essentially the initial layers of any standard image classification network, pre-trained on the ImageNet dataset. The authors use VGG-16. The fully connected layers at the end are implemented as convolutional layers. The final output of the base network is a feature map of size 19 x 19 x 1024.
<a href="https://medium.com/media/72b924db2658b910f0e28c7b2acd901f/href">https://medium.com/media/72b924db2658b910f0e28c7b2acd901f/href</a>
On top of the base network, 4 additional convolutional layers are added such that the size of the feature maps keep reducing until a final feature map of size 1 x 1 x 256 is obtained.
<a href="https://medium.com/media/44479382ab5ca79050e3ccf0d51a79b1/href">https://medium.com/media/44479382ab5ca79050e3ccf0d51a79b1/href</a>
The prediction layers are a crucial component of SSD. Instead of just using one feature map for predicting the classification scores and bounding box coordinates, several feature maps, representing multiple scales are used. This is where the idea of default boxes and feature map resolutions, discussed above, is used. Specifically, the layers conv4_3, conv7, conv8_2, conv9_2, conv10_2 and conv11_2(shown in the figure) are used for the bounding box predictions.
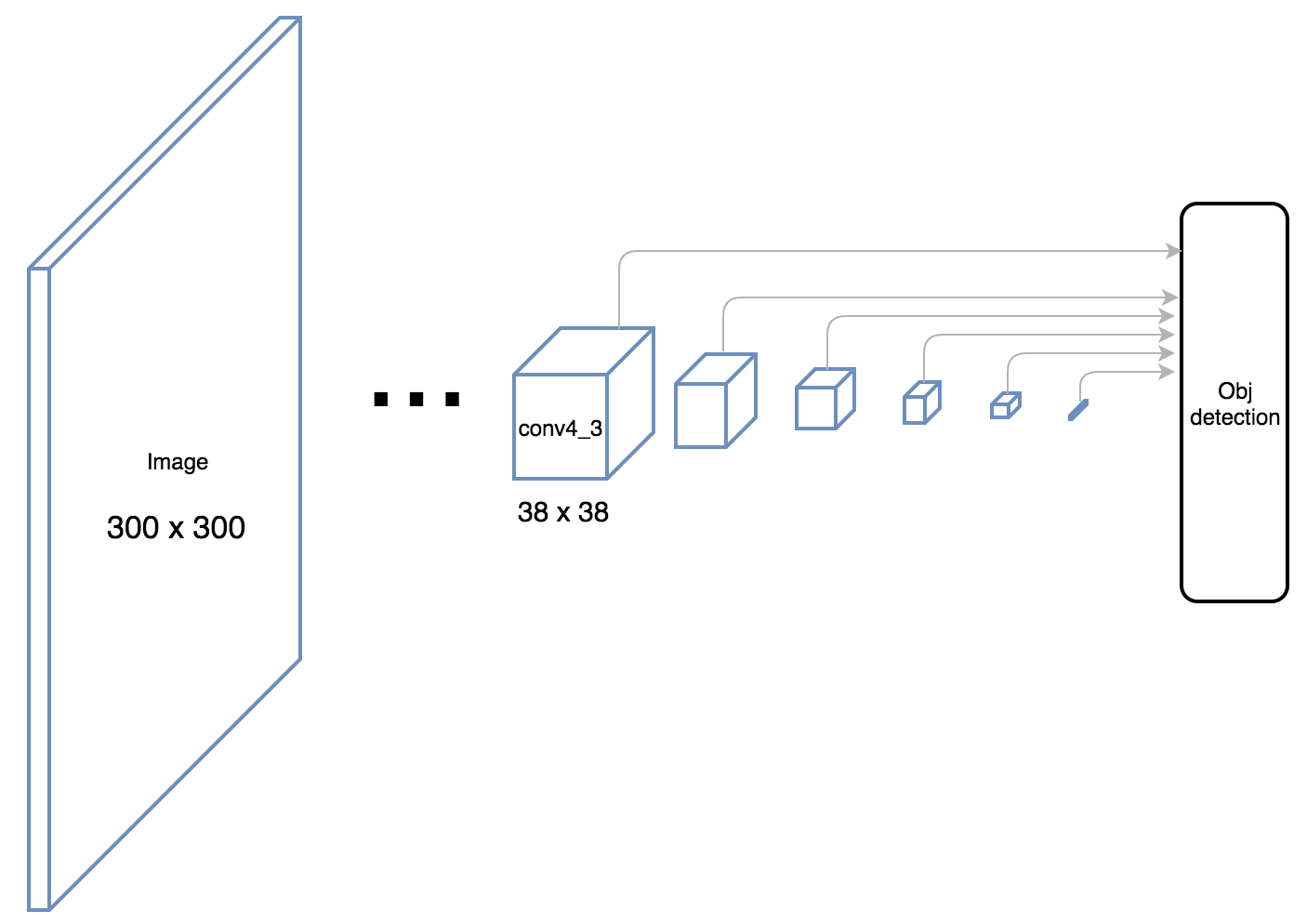
As shown in the image earlier, there are default boxes associated with each cell of a feature map and the number of such boxes — either 4 or 6 — is decided beforehand. Considering the number of classes (including the background class as class 0) to be C, each prediction is represented by (C + 4) numbers: C classification scores and 4 offsets: ∆cx, ∆cy, w and h, representing the offsets from the center of the default box and its dimensions. Thus, for a feature map with k default boxes per cell, the prediction layer is a 3 x 3 convolutional layer with k * (C + 4) channels.
<a href="https://medium.com/media/a738196427bf979dbed80ac6ee4bbd5d/href">https://medium.com/media/a738196427bf979dbed80ac6ee4bbd5d/href</a>
3. Forward pass
In this section, I’ll describe how the complete forward pass looks like. Before we move to the code, one important detail to specify is that it has been shown that the feature map corresponding to conv4_3 layer of VGG has a very different scale compared to the later layers.
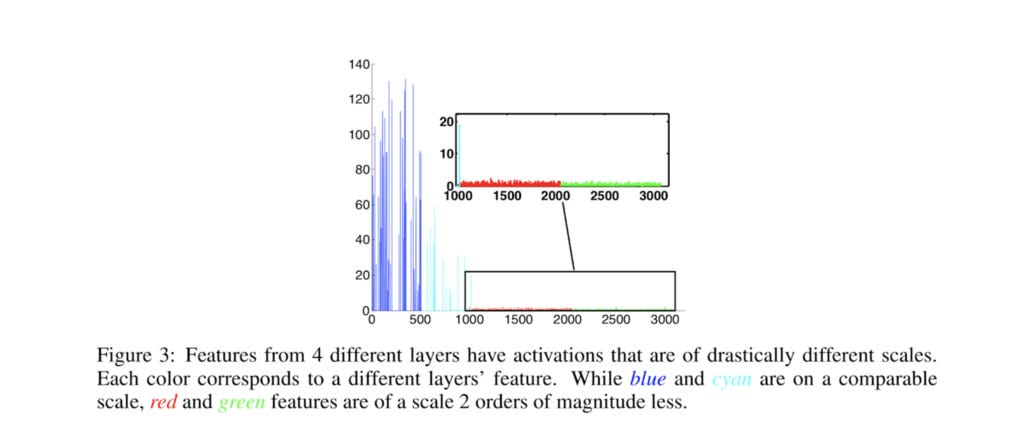
So, the features from that specific layer are normalized and set to an initial scale value of 20. The actual scale is then learned during back-propagation via the weight parameter. The code for the L2Norm layer is shown below:
<a href="https://medium.com/media/498e0c0415cc36ba830144094c887e94/href">https://medium.com/media/498e0c0415cc36ba830144094c887e94/href</a>
Finally, the forward pass through the network is shown below. sources contains the various feature maps that contribute to the final prediction.
<a href="https://medium.com/media/fdf563e0fb9719e17b55dab85f0014c0/href">https://medium.com/media/fdf563e0fb9719e17b55dab85f0014c0/href</a>
4. Choosing default boxes
As SSD relies heavily on default boxes, it is very sensitive to the choice of the default boxes, specifically their scale and aspect ratios. In the paper, the authors design the default boxes such that each feature map corresponds to a specific scale of default boxes along with a list of aspect ratios for each scale. The minimum and maximum scales, s_min and s_max, are set to 0.2 and 0.9. For the kth feature map (among m feature maps), the scale is chosen as:
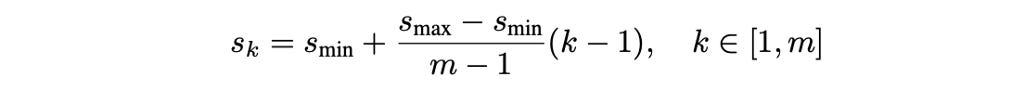
For a feature map corresponding to a specific scale and having 6 default boxes associated with it, the heights and widths of the default boxes are obtained as shown below:
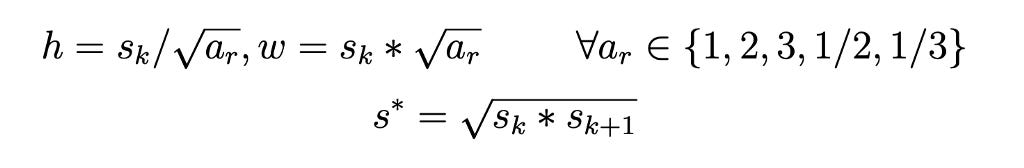
For each feature map, an additional default box of scale s* and aspect ratio 1 is added. Feature maps having only 4 default boxes do not use aspect ratios 3 and 1/3. The center of each default box is set as the center of the cell to which it belongs. The default boxes are defined in code as shown below:
<a href="https://medium.com/media/7d4a8ec4526692907c0f7cdf2a1c4402/href">https://medium.com/media/7d4a8ec4526692907c0f7cdf2a1c4402/href</a>
5. Training
The loss function used is the MultiBox loss, which consists of two terms: the confidence loss and the localization loss. The network outputs (C + 4) predictions for each of the 8732 boxes: C class scores and 4 localization offsets.
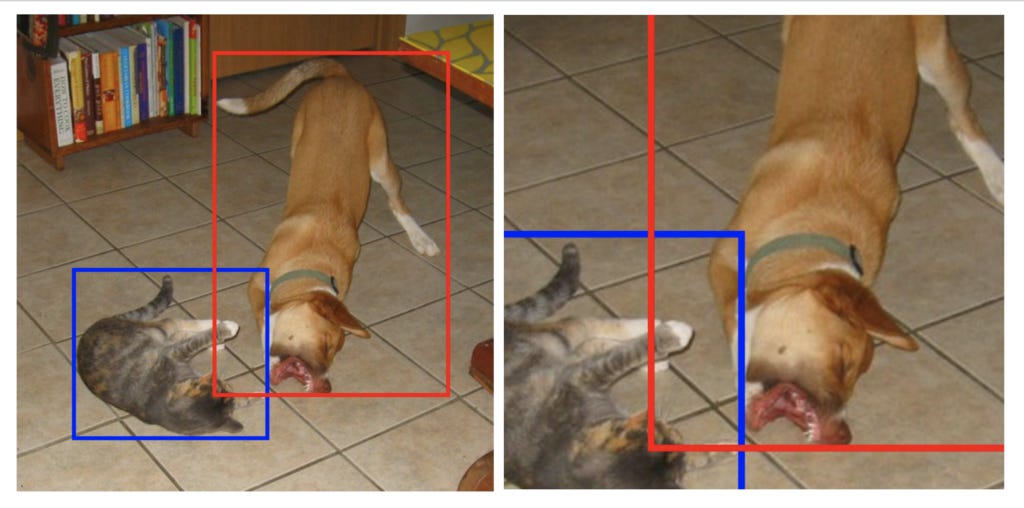
Anchor Matching: To train the network, all the default boxes are matched to the ground truth boxes. First, each ground truth box is matched to the default box having the maximum jaccard overlap. This is done to make sure that each ground truth box has at least one corresponding default box. Then, each default box is matched to any ground truth box having a jaccard overlap > 0.5. This essentially turns the problem into a multi-label problem for each box. The implementation below matches each default box to only the best matching ground truth, but it can be easily modified to incorporate the multi-label criteria.
<a href="https://medium.com/media/dbaa92d8f236b0d68ebdb44ac7bfea99/href">https://medium.com/media/dbaa92d8f236b0d68ebdb44ac7bfea99/href</a>
Loss function: The default boxes that didn’t get matched to any ground truth box are considered negative and contribute only to the confidence loss, whereas all the positively matched boxes add to the confidence loss as well as the localization loss. The confidence loss is essentially the cross-entropy loss while the localization loss is the Smooth L1 loss between the actual offsets of the default boxes to the ground truth boxes and the predicted offsets.

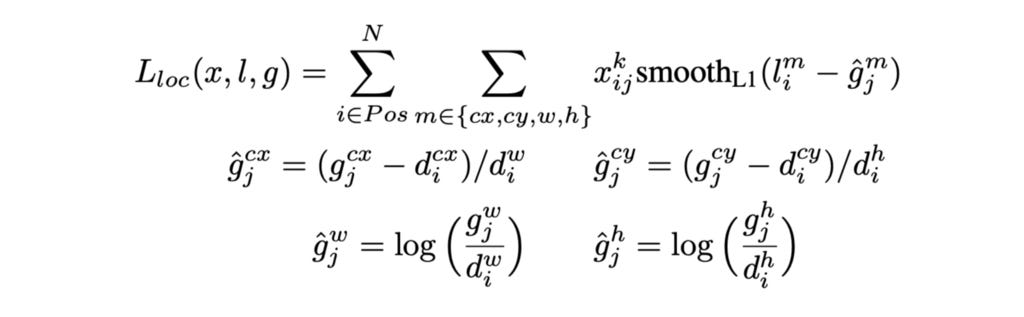
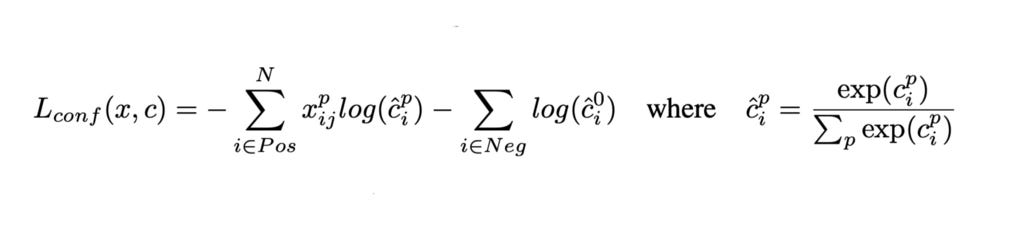
The final loss is given by a combination of both the losses where α is the relative weighing of the localization loss w.r.t the confidence loss (set to 1 by cross validation) and N is the number of positively matched boxes.
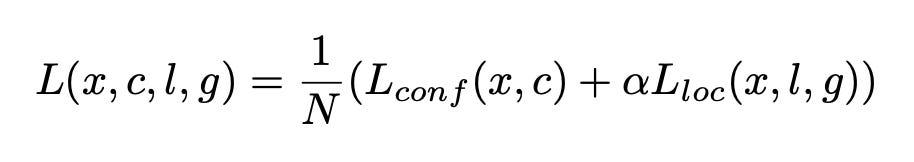
Hard Negative Mining: Most of the boxes, out of the 8732 default boxes, are negative. Using all the negative boxes directly would lead to a severe class imbalance during training and hence, once the matching is done, only those negative boxes having the highest confidence losses are retained such that the ratio between the positive and negative boxes is at least 1:3.
Data augmentation: Not using data augmentation leads to a major drop in performance. The important data augmentation strategies used are:

6. Inference
During inference, we now have 8732 boxes for each class (because we output C confidence scores for each box). Most of these boxes are negative and among the positive ones, there would be a lot of overlapping boxes, as shown below:
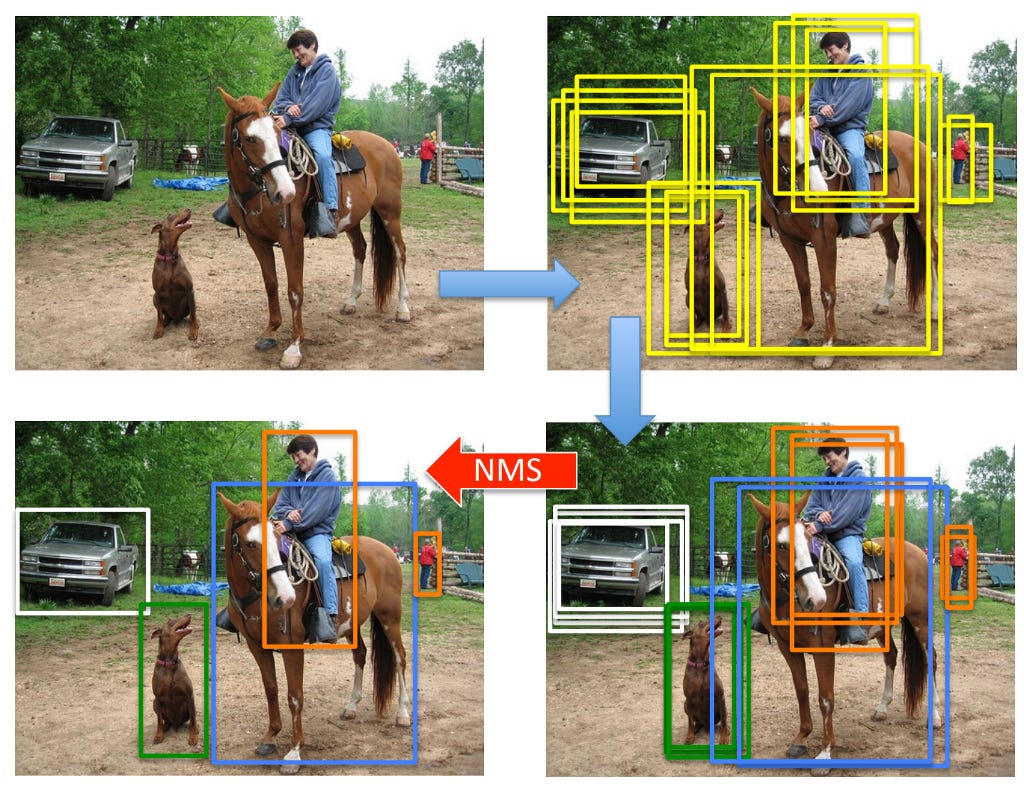
Upon receiving an image as input, first, default boxes are generated for all classes together (top right). Then, a confidence threshold of 0.01 is applied per class to obtain positive boxes (bottom right). Finally, Non-Maximal Suppression (NMS) is applied to get rid of overlapping boxes per class and return at most 200 boxes, using an Jaccard Index as the measure of overlap and an overlap threshold of 0.45. The need of NMS and how it’s done can be understood from this video. NMS essentially does the following (per class): sort the boxes based on the confidence scores, pick the box with the largest confidence score, remove all the other predicted boxes with Jaccard overlap > the NMS threshold (0.45 here), repeat the process until all boxes are covered.
<a href="https://medium.com/media/1bf6580ccec4a6e0303da144b2089d80/href">https://medium.com/media/1bf6580ccec4a6e0303da144b2089d80/href</a>
7. Discussion
Some general points to keep in mind regarding SSD are:
Data augmentation is very critical to better performance, especially for small objects.
The network is very sensitive to default boxes and it is important to choose the default boxes based on the dataset that it is being used on. A good strategy is to use K-means clustering to identify the right default box sizes.
Using stronger image classification networks as the base network - like Resnet, Inception, Xception - is likely to improve performance.
SSD does not work well with small objects. One potential reason for this, discussed in this paper, is that the earlier layers which have smaller receptive field and are responsible for small object detection, are too shallow. There is also a structural contradiction where the earlier layers are supposed to learn low-level features to be passed on to the higher layers whereas also learn high-level abstraction for correctly identifying boxes. This paper adds more context to the predictions and shows significantly higher performance on small objects. Using higher resolution images is also likely to improve performance on small objects.
80% of the forward pass time is spent in the base network. Significant improvement in inference time can be obtained by using MobileNet instead of VGG.
Using multi-scale feature maps for prediction is imperative to SSD’s performance. Adding more default boxes can improve accuracy at the cost of lower speed.
8. Resources
To summarize, SSD is the first one-stage detector to achieve an accuracy comparable to two-stage detectors while maintaining real-time efficiency. It uses the idea of default boxes and multi-scale predictions to directly regress on the bounding box coordinates, without the need of a proposal generation step. There are a few shortcomings of SSD as well, like it doesn’t work well with small objects, and a lot of ideas have been proposed to tackle its various issues. We’ll discuss these ideas in the next post.
I, personally, found this to be a very fascinating read and as I went into the implementation details, I only got more interested. This is a perfect example of the importance of small details and I definitely learned a lot while working on it. For someone looking to get their hands dirty with object detection, SSD is one of the best places to start. Also, if you found the post useful, make sure to give it a clap and share with other people who might benefit from it.
If you want to stay notified about my future posts, do follow me on Medium. If there’s anything that you might want to share with me or give any sort of feedback on my writing/thoughts, I would love to hear it as well. Feel free to connect with me on LinkedIn, or follow me on Github.
Real-time object detection part 1: Understanding SSD was originally published in Inveterate Learner on Medium, where people are continuing the conversation by highlighting and responding to this story.